


Le monde de l’économie quantitative est complexe. Il existe des dizaines de fournisseurs de données hébergeant des centaines de points de données différents et des milliers d’indicateurs individuels, tous dans le but bien précis d’aider les entreprises à prendre des décisions éclairées sur les opérations, le marketing et d’autres aspects fondamentaux d’un business réussi. Les analystes ou consultants en données, en affaires et en marketing, créent rapport après rapport afin d’ingérer ces données et extraire des informations factuelles qu’ils transmettent à la direction. Ceci, dans l’espoir d’avoir un impact sur le résultat net ou le chiffre d’affaires. Cette stratégie analytique plus traditionnelle a un atout majeur : des informations manuelles, d’origine humaine, qui font apparaître des schémas clairs dans les données et qui peuvent ensuite être facilement expliqués aux non-spécialistes des données.
Cette particularité place également l’analyse traditionnelle dans une position désavantageuse pour de nombreuses tâches découlant de la première constatation que nous avons faite dans cet article : le monde de l’économie quantitative est complexe. Les relations entre les indicateurs économiques mondiaux ne sont généralement pas évidentes. Il peut y avoir de multiples interactions qui modifieraient la relation entre X et Y, en fonction de la valeur de Z ; le PIB et les investissements publics dans la technologie peuvent être associés positivement l’un à l’autre, mais seulement si le gouvernement a une faible dette, par exemple. Il s’agit d’un cas relativement simple – les relations réelles cachées dans les ensembles de données sont souvent encore plus complexes que cela, car nous ajoutons de plus en plus de paramètres, ce qui ajoute effectivement plus de dimensions aux données. Le problème majeur est que peu d’humains peuvent visualiser ou penser en 4, 5 ou même 200 dimensions.
Les machines, en revanche, excellent dans ce domaine. Nous avons mis au point des algorithmes de calcul et des modèles statistiques capables de repérer automatiquement des tendances dans le désordre des milliers de dimensions. Lorsque cela est fait correctement, ils recherchent des ensembles de règles généralisables pour expliquer ce qui se passe dans un ensemble de données, un pouvoir que même l’humain le plus astucieux ne peut posséder (en fait, les humains ont tendance à voir des « modèles » qui n’existent pas en réalité !) Nous pouvons démontrer ce principe à l’aide d’un exemple.
Supposons que vous soyez une start-up cherchant à choisir un nouveau marché d’exportation pour votre produit. Vous recherchez un marché qui a connu une croissance de la demande d’importation pour la catégorie de produits que vous vendez, et vous constatez que le pays A connaissait une forte croissance, mais que celle-ci semble stagner depuis quelques mois :
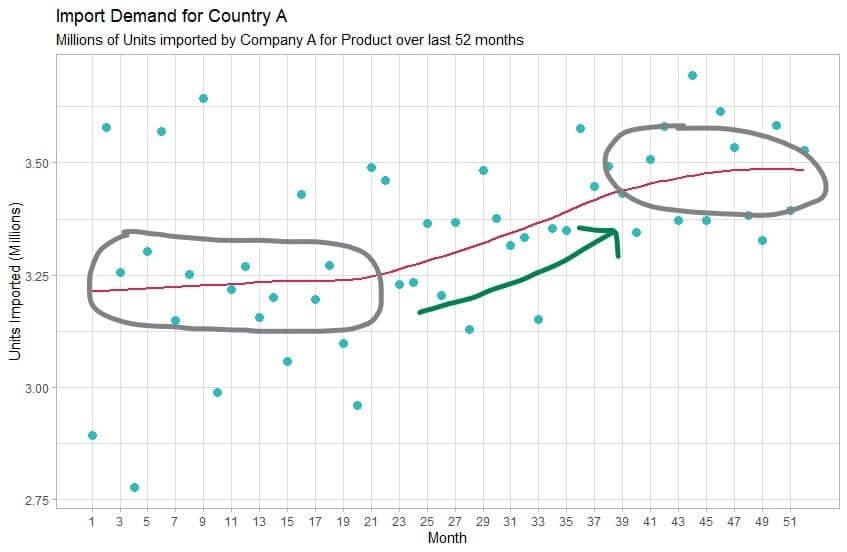
Évidemment, vous voulez vous assurer que cette stagnation de la croissance n’est pas permanente et, étant donné que le marché a connu une forte croissance de la demande pour ce produit dans le passé, vous pensez qu’il est plausible que cela se reproduise à l’avenir. En fin de compte, vous devez faire de votre mieux pour comprendre ce qui a provoqué la croissance en premier lieu et trouver des signes qu’elle pourrait se reproduire. Il est facile d’émettre des hypothèses sur une raison unique expliquant l’explosion et la stagnation de la croissance, mais étant donné la complexité de l’économie, il est extrêmement probable qu’il n’y ait pas une seule raison à cela, mais plutôt de nombreux facteurs qui se combinent pour créer l’effet observé dans le graphique.
En science des données, il s’agit d’un problème classique de série chronologique, où nous essayons de comprendre ce qui pourrait faire varier cette mesure dans le temps. Nous pouvons collecter de nombreuses autres mesures, telles que la croissance du PIB, les types de politiques adoptées par le gouvernement, les indices culturels, etc. de ce pays ainsi que d’autres marchés et les comparer les unes aux autres via un algorithme d’apprentissage automatique. Avec un grand spécialiste des données à la tête de ce projet, le modèle sera capable d’ « apprendre » les relations entre toutes ces mesures et de formuler des règles sur ces relations en quelques minutes. Ensuite, à l’aide de ces règles, le modèle peut être utilisé pour prévoir la demande du marché pour le mois, le trimestre ou l’année à venir (ou au-delà !) avec plus de précision qu’un analyste pourrait le faire en utilisant des méthodes heuristiques. Une prévision de ce modèle pourrait ressembler à ceci :
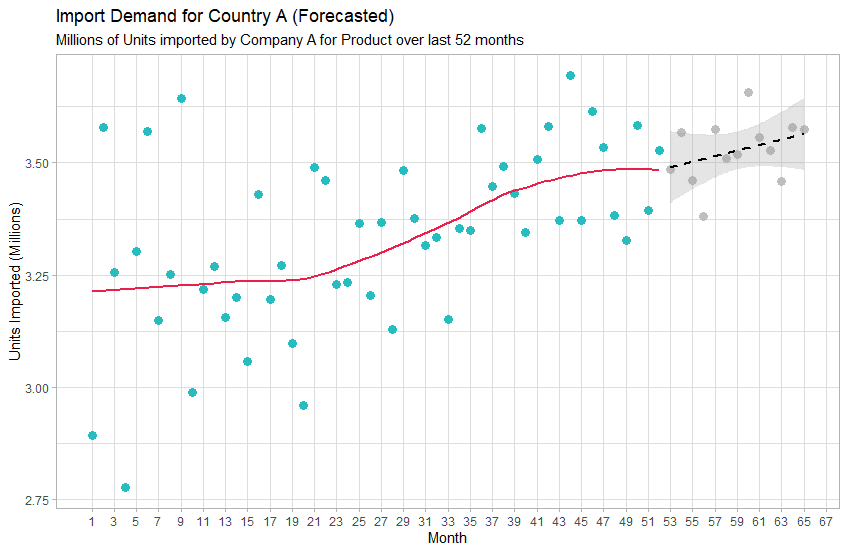
Dans ce cas, le modèle a déterminé, sur la base des relations entre les facteurs économiques qu’il a trouvés pour ce pays et d’autres, que la demande de ce produit sur ce marché va augmenter au cours des 13 prochains mois. Avec des spécialistes des données plus avancés et plus de temps, le même modèle pourrait être utilisé pour trouver les raisons de cette prévision – par exemple, pourquoi le modèle a prévu une augmentation de la demande plutôt qu’une diminution ou aucun changement.
Conclusion
Avec le développement de la puissance de calcul et la mise à disposition de nouvelles sources de données, la science des données et l’apprentissage automatique vont considérablement améliorer la capacité des entreprises à prendre des décisions informées. Cela est particulièrement vrai pour les problèmes de sélection de marché, où le fait d’avoir des indications concrètes sur les futurs paramètres économiques peut faire ou défaire le choix d’un nouvel exportateur. Si vous n’investissez pas encore dans la science des données, il est temps de passer à l’action.
